Sample Spreadsheet
Section 4 of the Toolkit gives guidance on how to set up a clean spreadsheet that's analysis-ready. For our example, we'll use the sample Excel spreadsheet provided, which is named examp03-04gr34.xls. This is a spreadsheet of data from real students in a TWI program at the third and fourth grade levels, so we have changed the ID numbers and removed the students' names. We deleted the students at the other grade levels because the spreadsheet would have been too big and unwieldy to use as an example.
To begin, download the sample spreadsheet. (If a window appears asking you to "open" or "save", click "save" to put a copy on your computer.) To view or work with a spreadsheet, you will need to have the Excel software installed on your computer. See Section 4 for information about accessing Excel.
We gave our spreadsheet that name to tell us it includes data on third and fourth graders in the 2003-04 and the 2004-05 school years. There's no rule in how to name a data file—whatever makes sense for you. However, having some indicator of the academic year(s) is really helpful.
When you have set up your own spreadsheet, or if you save this sample spreadsheet, you will save it in a file folder on your computer that makes sense to you, e.g., "Program Evaluation 2004" or "Program Data Files."
Look at the Excel spreadsheet and familiarize yourself with the column headings. You will see that the spreadsheet contains the following kinds of information:
- Student ID numbers
- Name (not included in this sample)
- Ethnic group
- Language (native or first language)
- Language group (ELL, R-FEP, EO)
- Grade level in 2003-04
- Grade level in 2002-03
- Grade level in 2001-02
- Grade level in 2000-01
- CST English Language Arts Proficiency Level in 2004
- CST English Language Arts Proficiency Level in 2003
- FLOSEM scores in English and Spanish from 2000 through 2004
- Aprenda Total Reading NCE scores in 2003 and 2004
- Whether the students were on free/reduced lunch in 2003 and 2004
- Whether the students were retained or referred for Gifted and Talented or Special Education in 2003 and 2004
The columns in the spreadsheet are not in the same order listed above; it is organized so that all of the variables for one year are next to each other. Also download the sample codebook: these variables are explained in more detail there (although the sample variable names in the codebook are not the same as the variable names in the sample spreadsheet).
As you look at the spreadsheet, note that we have taken our own advice and used numeric codes, which are explained in the Codebook. You may choose to use alphabetic codes if you wish. This is an important distinction we will draw.
Note too that the column headings are all 8 characters in length or shorter. That makes it possible to import the spreadsheet into the statistical program SPSS, which we will discuss in the next section.
From now on we will refer to the data we have listed above as "variables." For example, the ID number is a variable. So is the ethnic group, so are all the test scores. That's because the values in each column "vary." FLOSEM scores vary from 5-30. Language group varies from 1 to 2 or 3 or more (depending on how many language groups you have). The values of the variables are what make the data interesting, and they are what we want to find out about in our data analysis.
Importing the Spreadsheet Into A Strategical Program
You have familiarized yourself with the contents of the spreadsheet, and it is saved in the appropriate folder, which you have closed. [Normally, once you finished entering the data, you would go through it carefully for any mistakes and to make sure the codes were consistently entered—see Section 4 for more information on this.] We will now proceed to how to import the Excel file into the statistical program, and then, in the following section, how to carry out data analyses that answer various evaluation questions. It may seem painstaking at first, but after just a few times following the steps, it will become much easier, and you will have enough understanding to do your own simple analyses.
The guidance we give regarding the statistical program, and all the examples, use the Statistical Package for the Social Sciences (SPSS) Version 11.0 for Windows and Mac (we will provide examples that are the same whether you use the Windows or Mac version—if there are differences, we will highlight the differences for the Mac). Many other programs are available, and the nomenclature they use for the various processes may vary, but they should all provide similar features and be capable of the same analyses. Now, to get started, you open the statistical program, again in our case, SPSS.
You will see a window that asks "What would you like to do?" Down the road, when you have worked with a few statistics files, those will be listed, and you can choose one. For now, just close that window (click on Cancel).
You will now see a Toolbar at the top of the page. In the Toolbar, under File, the pull-down menu includes OPEN. To the right it says DATA. Click on that.
Now you have a window that says LOOK IN (on the Mac, it says Open File), and you will use the pull-down menu to locate the folder where you saved the spreadsheet (remember the file was named examp03-04gr34.xls). Select the folder with that file.
In the window where it says Files of Type (on the Mac, it says Enable), use the pull-down menu and scroll down to select Excel. You will see a list of Excel files in that folder. Choose the one you want, in this case, examp03-04gr34.xls
You will get a window saying, Open Excel Data Source (on the Mac, it says Opening File Options), and it should display the name of the selected spreadsheet. (On the Mac, you need to click the little box next to where it says Read variable names.) Click OK.
If the spreadsheet is "clean" in the way we described in Section 4 of the Toolkit, you should very soon see the spreadsheet in front of you, but now it's in SPSS format, not Excel.
But sometimes the spreadsheet isn't "clean," and instead of the data file you'll see a window with a series of error messages telling you that there was data of an unrecognized type in certain rows of certain columns. This can happen if you have an empty column, in our sample, the empty column of names. It can happen if you have mixed numeric data and alphabetic data in the same variable. In that case, you'll need to go back and clean up the spreadsheet.
Important tip: Make sure your alphabetic and numeric variables are correctly specified in SPSS. What does that mean? Look at the bottom left corner of the SPSS screen. You will see Data View and Variable View. If you select Variable View, you will get a list of all the variables in the data file. Next to the list of variable names is a list called Type. The variables that consist of numbers, e.g., test scores, grade levels, etc., should all say Numeric. If you have used letter codes in any of your variables, it should say String. If the wrong type is indicated, click to the right of the type (String or Numeric) within that same cell, and you'll get a menu that allows you to choose the correct type. It's especially important to make these corrections if for some reason your numeric data show up as string data. Having made any necessary corrections, at the bottom left, click Data View, and there's your data file, ready for analysis.
At this point it's a good idea to go up to File in the Toolbar, click Save As, and save this data file as an SPSS file in whatever folder makes sense to you. Where you see File Name, start typing the name. If it's the same name as your Excel file, it will do that for you in the PC version, but you'll have to type in the name in the Mac version. Make sure the extension says .sav, and you will have saved your spreadsheet as a statistical data file. It will not replace your Excel spreadsheet; it's still there.
A GOOD REMINDER – ALWAYS HAVE A BACKUP FILE!!! Sometimes you may make a change that you didn't mean to make, then save, and then to your horror, your data is all gone or changed in ways you didn't mean to. The way to save yourself from this agony is to Save with a different name. You can use the name, but add an a or b, or a 1 or 2 at the end. Then when you have the file the way you want it, you can delete the previous attempts at changing the file. The important thing is don't make big changes on a file if you don't have a copy of it somewhere!!
So, this is what it should look like on your screen (for the first 9 columns and the first 6 students:

Note at the bottom of your screen, you are in Data View, but if you click on Variable View, you’ll see the following:

So, if you see one of these views and you really want the other view, just click on the other tab at the bottom of the page, and you’ll see the view that you want.
Normally, what you would want to do is enter your codebook so that when you run analyses, you know what the numbers mean. That is, if you run an analysis to see whether some score differs for students of the different language backgrounds (variable name is language), you might forget when you do your analysis whether 1 was Spanish (or Mandarin or Russian, etc.) or 1 was English. So, it’s easier to enter the codebook.
We’re going to cheat for you, because we’ve already done that. In order to see how it would be done, you can now download examp03-04gr34b.sav (In Firefox, right click on this link and click "save link as...") and save it in the same folder that you chose earlier (it won't overwrite your first file because it has a "b" at the end of the name). To open it in SPSS, go back to the SPSS menu at the top of the page, click on File and then scroll down and click on Open, then across to Data. Now you should be in the same folder that you copied this other example SPSS file into, so click on examp03-04gr34b.sav. When it opens, you’ll see that the Data View is the same, but now the Variable View looks like the following:

You can consult the SPSS manual for more information about entering information in the Variable View:
- Labels—these are just longer names for your variables than the 8 character limit that SPSS has—it’s actually as simple as just clicking in the box and writing something)
- Values—this is also simple, just click the "..." in the cell, and add the code number (Value) and what you want it to mean (Label), e.g., Value: 1, Label: English.
- Missing Values—missing values tell SPSS to ignore cases in which the value is missing. This is important because if you’ve got a 0 for a student’s score, to SPSS it means that the score is 0. If to you a 0 means there is no data, your analyses will be really off, and your outcomes much lower than they should be. To avoid this, you would set 0 to missing (in "discrete missing values") so that SPSS interprets it correctly. It is quite easy to do—very intuitive.
Analyzing Categorical Data
So far, we have gotten the data file ready to go. Now it’s time for the fun part, finding out what all that data can tell you about your students. We will work through a series of evaluation questions to demonstrate various kinds of data analysis. All of the procedures we will use will be found under Analyze in the Toolbar at the top of the page. We will demonstrate Descriptive Statistics, which includes Frequencies, Descriptives, and Crosstabs, as well as Compare Means.
We’ll start with a few very simple questions. The first set of examples will deal with categorical data, as described in Section 5 of the Toolkit.
Question 1: How many 3rd and 4th graders were enrolled in the program in 2004-05?
This question merely asks for a frequency count of the students in the categories of 3rd and 4th grade in the academic year of 2004/05.
In the Toolbar, click on Analyze, click Descriptive Statistics, and then choose Frequencies. You will see a list of all the variables in the data file. Find and select grade04, then click the arrow pointing to the window called Variable(s), and grade04 will appear in that window. You will then see it show up under Variable(s).

You could add more variables if you wanted. To remove a variable, click the arrow when it is pointing to the list of variables as in the above illustration. Click OK, and then you get the frequency count for Grade04. This is what you will see:
If you look at the top of this page, you’ll note that you’re no longer looking at the window that has the Data View OR Variable View. You’re in a new window that is called Output – SPSS Viewer. When you want to get back to the Data window, just go to the Toolbar, click Window, and then you can click on the data file examp03-04gr34b.sav. For now, stay in the output window.
You can save the output that you create, or even print it out if you want. You can just go to the Toolbar, Click on File, scroll down to SAVE AS, and then give it a name. We would suggest actually naming it something that will be helpful for you to remember. Otherwise, SPSS will name it Output. Over time, you can collect a whole bunch of Output files and you won’t remember which one had which analysis on it. Output files have an .spo extension.
By the way, you can also Open output files if you want to use one that you generated previously. You use the same process as you did in opening the SPSS file; that is, you go to the Toolbar, click on File, then down to Open, then across to Output (instead of Data), and you’ll see your list of Output. Just select the one you want and it will appear on your screen. You can even open more than one output if you want, but we don’t recommend that until you’ve used this many times and understand in which window your output is printed.
Getting back to the analysis, what you see in the tables you created is raw SPSS output. It shows that there were 60 third graders and 62 fourth-graders. It tells what percentage of the students was in each of those grades. “Valid Percent” can differ from Percent: it would tell the percentages if there were any cases where the grade level was not listed.
Just to give you an example, we went back and deleted the grade level from 5 third graders. Look at the output you would get if you had not recorded the grade level for 5 students.
You’ll see that now you have the top table telling you that there are 5 cases with missing data for Grade 04. And you’ll see that you now have only 55 third graders, accounting for now 47% of the students for whom you have data (instead of the original 49%). [If this were an error—that is, you knew you should have grade levels for all students—you could go back and correct your Data file (just fill in the missing data—you CAN make corrections on the data in SPSS. You can add, delete, change, etc). Just don’t forget to SAVE.]
If you tried this along with us, close your data file WITHOUT SAVING so that you have the original data with all grade levels filled in. Then open examp03-04b.sav again to get ready for the next exercise.
Now let’s try a just slightly more sophisticated question.
Question 2: How many EP and ELL students were in each grade level in 2004-05?
This is a Crosstabs question. Section 6 of the Toolkit explains that a Crosstabs analysis tells how many cases there are in the intersection of two variables, in this case, language proficiency group (langroup) and grade level (grade04). Alternately expressed, how many students were in the category of EP and 3rd grade? EP and 4th grade? ELL/FEP and 3rd grade? ELL/FEP and 4th grade?
Again under Analyze, select Descriptive Statistics, and then select Crosstabs. You will again see all the variables from the data file listed on the left. You will see a Row(s) window and a Column(s) window. We chose to put the grade level in the rows and the language proficiency groups in the columns (though we could have put Grade 04 in Column and Langroup in Rows). Select Grade04 and then click the arrow pointing to the Row(s) window. Then select langroup (Lang group at entry) and click the arrow pointing to the Column(s) window. Now you should see the following:
After you click "OK," here’s the output you would get from this analysis:
It shows that of the 60 3rd-graders, 42 had entered as ELL or FEP, and 18 entered as EP. Of the 4th-graders, 42 had entered as ELL or FEP, and 20 had entered as EP.
If you wanted percentages associated with these values, you would use the same procedure as before (Analyze, Descriptives, Crosstabs), but where it says Cells, you would click on that, then click in the Row box and the Column box under Percentages (then click Continue, then OK). Then you would see this:

You would also get the Case Processing Summary, but we didn’t copy it here.
Now you wouldn’t have to get out your calculator to determine what percentage of your third graders was ELL/FEP (70%) and what percentage was EP (30%). This table also tells you something else: You can determine what percentage of your ELL/FEP students were at each grade level. In this case, 50% of your ELL/FEP students were third graders and 50% were fourth graders.
The exact same Crosstabs procedures could be used to find out such things as: What were the ethnic groups of the ELL/FEP and EP students?, How many ELL/FEP and EP students were referred for Special Education or Gifted and Talented?, and so on.
Let’s move on to some outcome data. So far, we’ve used crosstabs to describe student groups. However, it can also be used to analyze categorical test scores. For example, the California Standards Test (CST) provides the categories with the numeric codes we are using:
1 = Far Below Basic
2 = Below Basic
3 = Basic
4 = Proficient
5 = Advanced
We could ask the following evaluation question:
Question 3: How did ELL/FEP and EP students score on the CST English Language Arts test in 2004-05?
This question, like the previous one, asks about numbers of students in two different categories, language group and CST Language Arts scores, so again, Crosstabs will provide the answer.
As before, under Analyze, choose Descriptive Statistics, then choose Crosstabs. Let’s use CST levels for the rows and language groups for the columns. Select cela_p04 (CST ELA 04 perf level) from the Variables list, and then click on the arrow to put it into Row(s). Then select langroup (Lang group at entry) from the Variables list and click on the arrow to put it into Column(s). If you want percentages instead of just numbers, then click on Cells, then click in the box next to Rows and Column under Percentages. Then click Continue, then OK, and you will see:
As explained in Section 6 of the Toolkit, the direct comparison between the two groups would be made clearer by presenting the data as percentages. Now you can see that of the 81 ELL/FEP students, 12.3% (or 12%) were in the Far Below Basic category, 32.1% (32%) in Below Basic, 30.95% (31%) in Basic, 22.2% (22%) in Proficient, and 2.5% (3%) in Advanced.
Note that this analysis was for all students in the program and did not differentiate by grade level. It would be possible to do a three-way Crosstabs adding grade level (you would do it the same as with the two-way analysis you did, but you would add Grade04 to the last box labeled By:), but the output is a little more complicated to interpret.
A helpful tip: It’s often useful to isolate a certain group of students, say, the 2003-04 4th-graders, for analysis, excluding all the other students. That can be done through a procedure called Select Cases. Here’s how:
First, make sure you’re in the window where you can see your data and not in the Output window (you have to go to Window and select the data file you’re using—examp03-04gr34b.sav). Now, locate Data on the Toolbar. Use the pull-down menu and choose Select Cases. You will see a list of the variables in the data file, and you will see the option “If condition is satisfied.” Select that option and then click If…. Now you will see another screen with the variables. Choose the one you want to isolate (in our example, grade04), click on the arrow, and grade04 will appear in the window. Now click on the equal sign below (=), then type in or click on 4. You will see the following:
Now click Continue. You are back to the previous screen. Click OK to run the select cases procedure. From this point, only the 2003-04 4th-graders will be included in the analysis.
In fact, only 4th graders will be included in all the remaining analyses you run until you go back to this step and click on Data, Select Cases, and then click on Select All Cases, then OK. It’s important that you NOT click the box on the bottom of the Select Cases screen that says Unselected Cases are Deleted. If you do, all your cases other than fourth graders will be deleted from your file for the remaining analyses, and then from the data file forever if you save your file. So, be sure you keep the default Unselected Cases Are: Filtered as the one that is selected.
If we run the same Crosstabs again (to get there, Analyze, Descriptive Statistics, Crosstabs) using only the 2003-04 4th-graders, you might notice that the Crosstabs screen is still set to the analysis we did last time. That is very convenient if we want to run the same analysis. Anyway, we would get the following output. Notice that on the output, there is nothing to tell you that this is only the fourth graders. So, if you want, you can add a title that tells you that. Otherwise, you may forget which table belongs to which group. To add a title to the analysis, you just click in your output on the word Crosstabs, and then type in anything you want—we typed in 4th Grade.
The previous Crosstabs analysis included 3rd and 4th-graders. This one includes only 4th-graders. The same process could be followed for any group, such as 3rd-graders, for separate analyses of their scores. However, if you want to do that for all grade levels, it’s kind of a pain to keep selecting cases for each grade level, so we can use a different procedure that's just as easy.
Follow the steps above to Select All Cases (in the Toolbar, under Data, Select Cases, All Cases, OK) to get back to where we started. Then, go to Data just like you did for Select Cases, but now instead of clicking on Select Cases, click on Split File. Once you are in Split file, you will see the list of variables in the left box just like you’ve seen with other analyses and Select Cases. Click on the circle next to Organize output by groups, then click on the variable that you want to organize your output by—in our case, grade04 (though it could also be langroup or ethnic, etc). Click on the arrow to put it in the box, then click on OK. Now, go back to Analyze, Descriptive Statistics, then Crosstabs, and click OK (see how easy it is when you’re running the same analysis?). Now you’ve got the same data for each grade level:
Two important points to remember:
- This is an example of the value of using numeric codes. Let’s say you wanted to isolate EP students for analysis, but you only used the letter code, not a numeric code. You would not have been able to use Select Data.
- After you have run all the analyses for the group you isolated, go back to the Select Cases screen and click on All Cases. Otherwise your subsequent analyses will also be limited to that group even if you intended to include other groups.
ANOTHER HINT: You can PRINT just the analyses you are interested in. In the Output window (looking at the analysis), go to the column on the left and just click on the analysis you want to print (click on Crosstabs). You’ll notice that there are boxes around this information. Now go to File, then Print and you get a typical print command like on a word processor. Select print and it will print out your analysis.
Also, if you want to DELETE information, you can click on the analysis and you’ll see the boxes around the analysis again, and just hit your DELETE key. The analysis will be gone. Pay attention to what you are deleting so you don’t delete something you really wanted. Remember to save the output file occasionally (or frequently).
To recap, the above analysis was a snapshot of the performance of two groups of students, but we are also interested in progress over time, that is, improvement. We could ask another evaluation question:
Question 4: Did program students show progress on the CST English Language Arts test from 2003-04 to 2004-05?
A very simple way to answer this question would be to run two frequency counts under Descriptive Statistics, using the variables cela_p04 and cela_p03. Then you could see if more students scored in the upper levels the second year than the first year. However, we can offer a more detailed look at growth, but to do that, we need to create a new variable, one that for each student compares the student’s performance each year. In other words, we will create gain scores. (This would also eliminate students who had scores only one year or the other, hence did not contribute to the picture of “growth” or “progress.”)
To create the students’ gain scores on the CST English Language Arts test from 2003 to 2004, locate Transform on the Toolbar (again, you have to be in the window in which you’re viewing the data file, not the output file). On the Transform pull-down menu, select Compute. That will give you a window with a small window for Target Variable and a list of the data file variables.
Where it says Target Variable you can type in the name of a new variable you want to create. For purposes of this example, we will create a new variable that we’ll call celagain (cela for the CST ELA test and gain for the gains we want to compute). You see an equal sign after the Target Variable box. To create the new variable we will click first on cela_p04 in our list of variables, then on the arrow pointing to the other blank window. That puts cela_p04 in that window. Then we click on the minus sign (-), then scroll down until you find cela_p 03 (CST ELA 03 Perf Level) and click on cela_p 03, then on the arrow again. You should see the following in the Compute Variable screen:
This gives us the definition, celagain=cela_p04 - cela_p03. In other words, we are subtracting the 2003 scores from the 2004 scores. We assumed the 2004 scores would be higher, so the new values in the gain score variable would mostly be positive. If a student remained at the same performance level, the value would be zero. If the student gained a level, the value would be 1. If the student dropped a level, the value would be minus 1 (-1). (Don’t forget to click on OK to make this new variable.)
Now we want to find out what the gains were for EP and ELL/FEP students, so we run another Crosstab (Analyze, Descriptive Statistics, Crosstabs). This time we use our new variable—celagain (do you see it at the end of the list of variables in the Crosstabs screen?) and insert it into the rows (to get rid of the cela_p04, highlight it and move it back into the list of variables by clicking on the arrow that is now pointing left), and keep our language groups in the columns, and we get:
Notice that our analysis is still organized by grade level because this was after we used Split File. (If we had wanted to turn that off, we would go back to Data, Split File, and click on Analyze All Cases, do not create groups. In that case, our analyses would have been for all grade levels.)
The output shows that from 2003 to 2004, 2 third grade ELL/FEP students and one third-grade EP student declined a level, but no fourth graders did. Fourteen (39%) third grade and six (17%) fourth grade ELL/FEP students, as well as 35% each of third and fourth grade EP students remained at the same level, and so on.
Using the Crosstabs analysis you could also find out where the gains and losses occurred. (We’ve turned off Split File for this analysis, though you could leave it on if you wanted—either by grade level or by langroup.) There are two ways to do this: In the Crosstabs analysis, use the 2003 scores as the rows and the celagain scores as the columns, and you can see:
Seven students (23%) who scored at Level 1, Far Below Basic in 2003 (follow across the top row) remained at that level. Sixteen students (53%) who scored in Level 1 in 2003 gained one level, to basic; etc.
OR:
Using the Crosstabs analysis, you could use the cela_p03 as the row and cela_p04 as the column.
Looking at the students in 04 who scored at Far Below—across the first row—7 (23%) had also scored as Far Below in the previous year (they are a 0 gain in our previous chart looking at gain scores). Of the Far Belows in 04—now looking down that column—2 (22%) had been at Below Basic the previous year (they are a -1 gain, or loss). And so on.
As you can see, there are different ways of looking at the information. The important point is understanding these tables so you can interpret the information. Be sure that you use the correct percent. To make sure you are using the correct percent, locate the 100% and move up the column or left across the row from there. Also, think about the focus you want to take. Do you want to look at the current students and see where they were the previous year, or do you want to look at where they were the previous year and where they are now? Both will give you similar information, but require looking at the table somewhat differently (whether you look at 04 students and go down the columns, or at 03 outcomes and go across the rows).
Analyzing Interval Data
Section 6 of the Toolkit explains the difference between categorical and interval data. The preceding examples used categorical data and showed different ways to count how many scores occurred in different categories.
Interval data are more fine-tuned, and more can be done with them statistically. The main analysis of interval data uses averages (means). The sample spreadsheet contains examples of interval data, the FLOSEM scores in English and Spanish and NCE scores on the SABE2 test.
To offer an example, let’s say that you want to answer an evaluation question about changes in English FLOSEM scores during the students’ five years in the program:
Question 5: Did students in the program show an increase in English proficiency as measured by the FLOSEM during their time in the program?
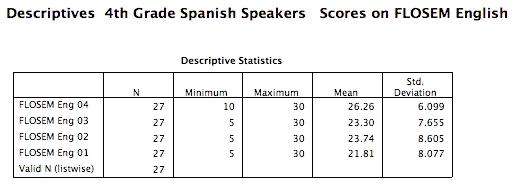
If you merely want to know what the average was for scores in a given variable, just go to Analyze, then choose Descriptive Statistics, then select Descriptives. You’ll see the list of the variables on the left—just like you’ve seen many times before. One by one, select flose04 (FLOSEM 04 Eng), flose03, flose02, flose01 and flose00. These are the students’ English FLOSEM scores for each of the years 2000 through 2004. As you select each one, click on the arrow to place the variable in the window that says Variable(s). Then click OK, and you get:

The output shows the number of students with scores (N), the lowest score in the variable (Minimum), the highest score (Maximum), the average score (Mean) and the standard deviation. (Standard deviation is explained in Section 6 and the glossary.)
This illustrates how to use Descriptive Statistics and Descriptives to obtain averages. However, the data are not very interesting, for two reasons. They combine scores for English speakers and Spanish speakers, and they combine scores across two grade levels, 3rd and 4th. Let’s fine-tune the question:
Question 6: What progress do current 4th-grade Spanish speakers show in English proficiency as measured by the FLOSEM during their participation in the program?
To narrow the analysis to the students who are both native Spanish-speakers and in fourth grade, we will use the Select Cases feature as we demonstrated in the discussion of Question 3, above. Again, go to Data in the Toolbar, and on the pull-down menu choose Select Cases. Then click If condition is satisfied, and then If. On the next screen, you have the list of variables (you might still see the previous variable we selected; we want it there, but if you had wanted to replace it, you could have highlighted it and clicked on the arrow pointing left and it would have moved out of the box). We want to select for the 2003-04 4th-graders, so select grade04 (or keep it in the box, if it’s still there), then click the little arrow pointing to the window. “Grade04” will show up there. Now click on the equal sign (=), then type in or click on the 4. Now you have limited the analysis to only 4th-graders.
But we’re not finished. We also want to limit the analysis to native Spanish speakers. The cursor should be just behind the 4 in the window. Now click the ampersand (&). Now in the variable list, select language (Primary Language), and click on the arrow pointing at the window. “Language” is now in the window following the ampersand. Again, click on the equal sign (=) and type in or click on 2. Remember, the codebook says that the code of 2 in language designates native Spanish speakers. You should see the following:

Click on Continue, and on the next screen you see click OK, and then you’ll see your data file again. Here’s what you have done: You have told the program to conduct analyses on cases (students) only if they are in 4th grade and they are native Spanish speakers.
Now you can do the exact same analyses as you did for Question 5, calculating the English FLOSEM means for each year, 2000 through 2004, but only on Spanish-speaking 4th-graders. If you have continued working with us here in the program since you did Question 5, when you go to Analyze then Descriptive Statistics then Descriptives, you will see those variables are still in the Variable(s) window, and you only have to click on OK to get the new statistics based only on 4th-grade native Spanish speakers (if they are not in the window, just highlight the variable, click on the arrow to move it into the Variable(s) window—do that for flose04, flose03, flose02, flose01, flose00). Here’s the output, with the addition of a title to remind us which group we’re selecting (remember to click on Descriptives in the output and you can add whatever kind of title you want):

The larger numbers of cases for the more recent FLOSEM scores suggest that many Spanish-speaking students entered the program later. What if we want to limit the analysis to students who had been served since 2001?
We would return to Select Cases, and add a series of conditions. Click on the ampersand (&), then, one by one, choose each year’s FLOSEM-English scores, and for each, specify >=5. This is what you would put into the box (you could even copy and paste this in): grade04=4 & language=2 & flose04>=5 & flose03>=5 & flose02>=5 and flose01>=5.
Here’s why. You listed those years because you only wanted scores for students served each of those years. The minimum possible score on the FLOSEM is 5, so by specifying >=5 (greater than or equal to 5), you have made sure you only have students with scores each of those years. If they did not participate in those grades, they won’t have a score and will be excluded. Then when you go back to Analyze, Descriptives and Descriptive Statistics and click on OK, you will get:
Another simpler way of getting only students who were there for each year is to use a different statistical procedure. Go to Analyze, then General Linear Models, then Multivariate. Now you see the common, by now, list of variables. Highlight the same list of FLOSEM variables and move them into the box called Dependent Variables. Now click on Options near the bottom of this screen. Now click in the box next to Descriptive statistics (under Display). Then click Continue and then OK. Now you’ll get some complicated analyses, but the top box—called Descriptive Statistics—will be the same means and standard deviations as with the previous procedure. We’re not even going to trying to explain the rest of this procedure. That’s a high level statistics class. So, you could delete those boxes.
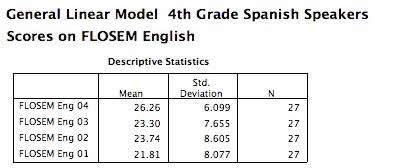
Now if you wanted to get that information for each combination of grade levels and student language backgrounds, you could use your Split File (Under Data) to do so.
Sometimes it is interesting to make a direct comparison of two groups of students on one measure at the same time. We did that above when we compared EP and ELL/FEP students on the California Standards Test of English Language Arts, using Crosstabs. We used Crosstabs because scores were reported in categories. To compare groups using scores on an interval variable, we will use compare means. Let’s illustrate that with the NCE scores on the SABE2 Total Reading and compare 4th-grade students of different proficiency levels (ELL vs. FEP vs. EP). That will give us an idea of whether, on average, the English-speakers have acquired enough Spanish by 4th grade to perform comparably to the ELL and FEP students, and whether the ELL differ from the FEP students in their native language. Here’s our evaluation question:
Question 7: How do fourth-grade students of different language proficiency levels compare in Spanish reading as measured by SABE2?
To make this comparison, first, we need to limit our analysis to students in the 4th grade, using the Select Cases feature under Data (if you need a reminder of how to do that, go to Question 3 above). Having done that, we’ll go to Analyze in the Toolbar, and in the pull-down menu select Compare means, which will offer another menu, Select Means.
Now you see the variable list on the left, and two windows. The upper one says Dependent List, the lower one Independent List. The dependent variable is the one we want the averages on (e.g., Spanish reading, or srt04n), the independent variable tells which groups (e.g., langrp04—we’re using langrp04 because it distinguishes between students who are ELL and FEP).
So we select srt04n (Span read total 04—the 2004 SABE2 Spanish Total Reading NCE scores), click on the arrow to the Dependent window, and srt04n is placed there. Then we select langrp04 (the ELL vs FEP vs EP), and click on the arrow to the Independent Variable window. Click OK, and we get our output:

We know that an NCE of 50 is the statistical average for the norm group, so we know that the means of all three groups—69.84, 77.20, and 64.85 are all well above average, and that FEP students scored higher than ELL students, who scored higher than EP students.
The same procedures can be used to compare any groups that are coded in a variable (e.g., native language, language group, ethnic, etc.) on any measure that uses interval scores (e.g., scale scores, NCE scores, scores on measures such as FLOSEM)